
How Do Scientists Use Claude Code?
Measuring Claude Code adoption among 16,000 scientists on GitHub

How to Win the AI For Science Race
In the near-term, “winning the AI for Science race” is downstream of a simple metric: which country gets the largest proportion of their STEM graduate students using the best AI coding tools available. 1
But right now, we have almost no empirical understanding of whether that’s happening.
AI is moving so quickly that sense-making on the ground is difficult in any sector, but in science the gap is especially stark. Within the bubble of SF’s AI economy, it feels like everyone is already moving on AI — a massive VC infusion has stood up entire supply chains of agent providers, domain-specific AI companies, and data infrastructure, to say nothing of general software startups that are increasingly “AI-first.”
But the rest of the country is still catching up.2 I still meet STEM graduate students who are writing Python scripts entirely by hand — not out of principle, but because Claude Code simply hasn’t reached them yet. The “Claude code moment” has not reached every part of the economy and the same is true for science.
Because AI capabilities continue to evolve so quickly, it is hard to make sense on what is actually happening on the ground — including in AI for Science.
This post is a first attempt to measure the diffusion of AI coding tools into scientific work. Leveraging the fact that Claude Code commits are default co-authored, and that we can use ORCID-GitHub profile links as a proxy for “scientists who code,” we can begin to measure how many scientists use Claude Code, what kind of scientists use it, and what they use it for.
We define “scientists” in this post as:
ORCID profiles who include a github profile link in their bio or profile description
have at least 1 commit on github in the past year
have at least 1 peer reviewed publication on ORCID in the past 2 years3
Out of ~14M total ORCID profiles, we identified 15,933 scientists (0.1% of ORCID profiles) who fit this definition. Our dataset selects for scientists who both maintain ORCID profiles and link to active GitHub accounts — a narrow slice of computationally active researchers — and the small sample of 331 Claude Code users means breakdowns by field, country, or seniority are directional, not definitive. Full Github repo here.45
How Many Scientists Use Claude Code?
As of February 15, 2026, ~2.1% of scientists with ORCID-linked GitHub profiles use Claude Code. Extrapolating from current growth rates, we’d expect ~10% of “scientists” in our dataset to use Claude Code by end of 2026.
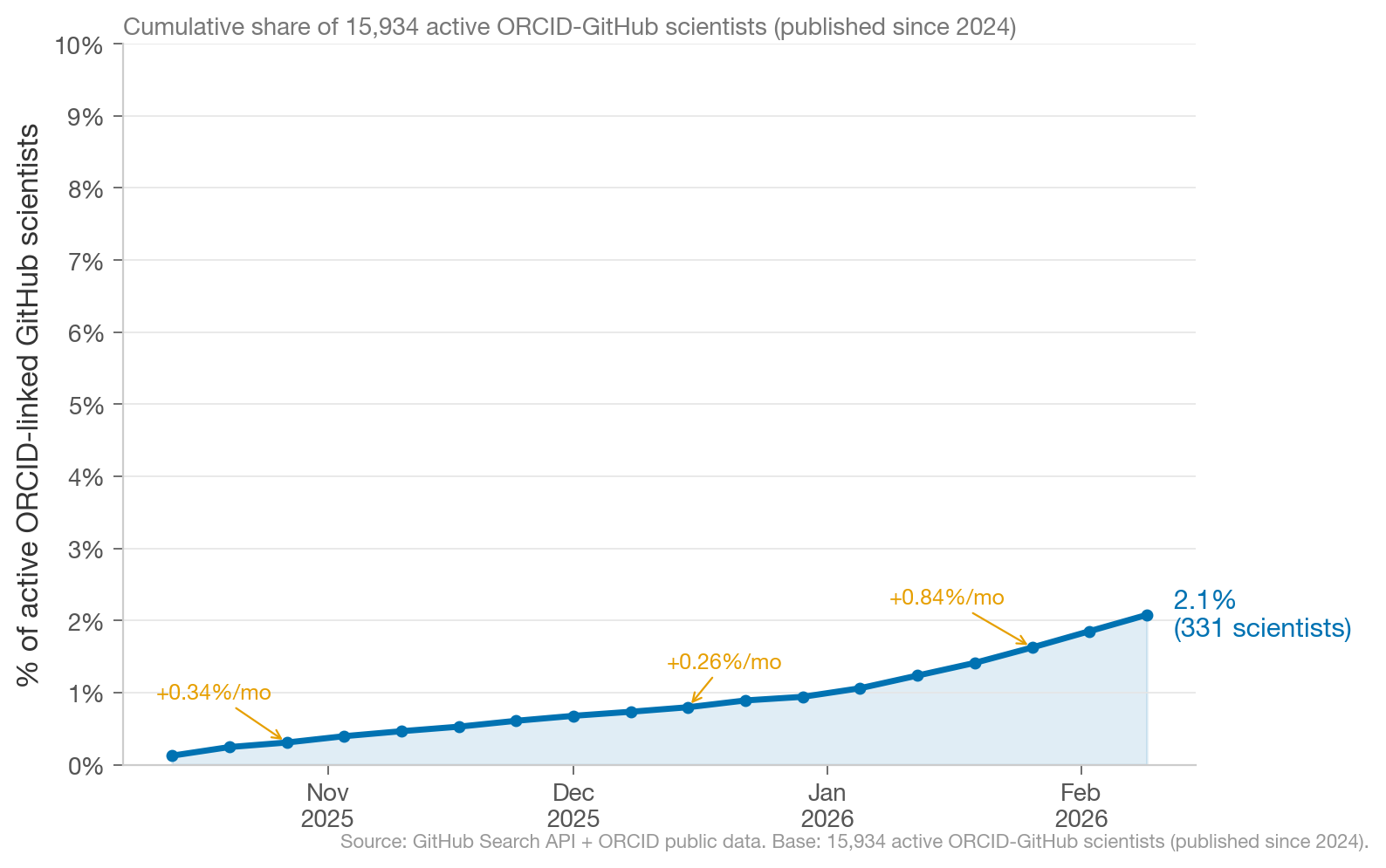
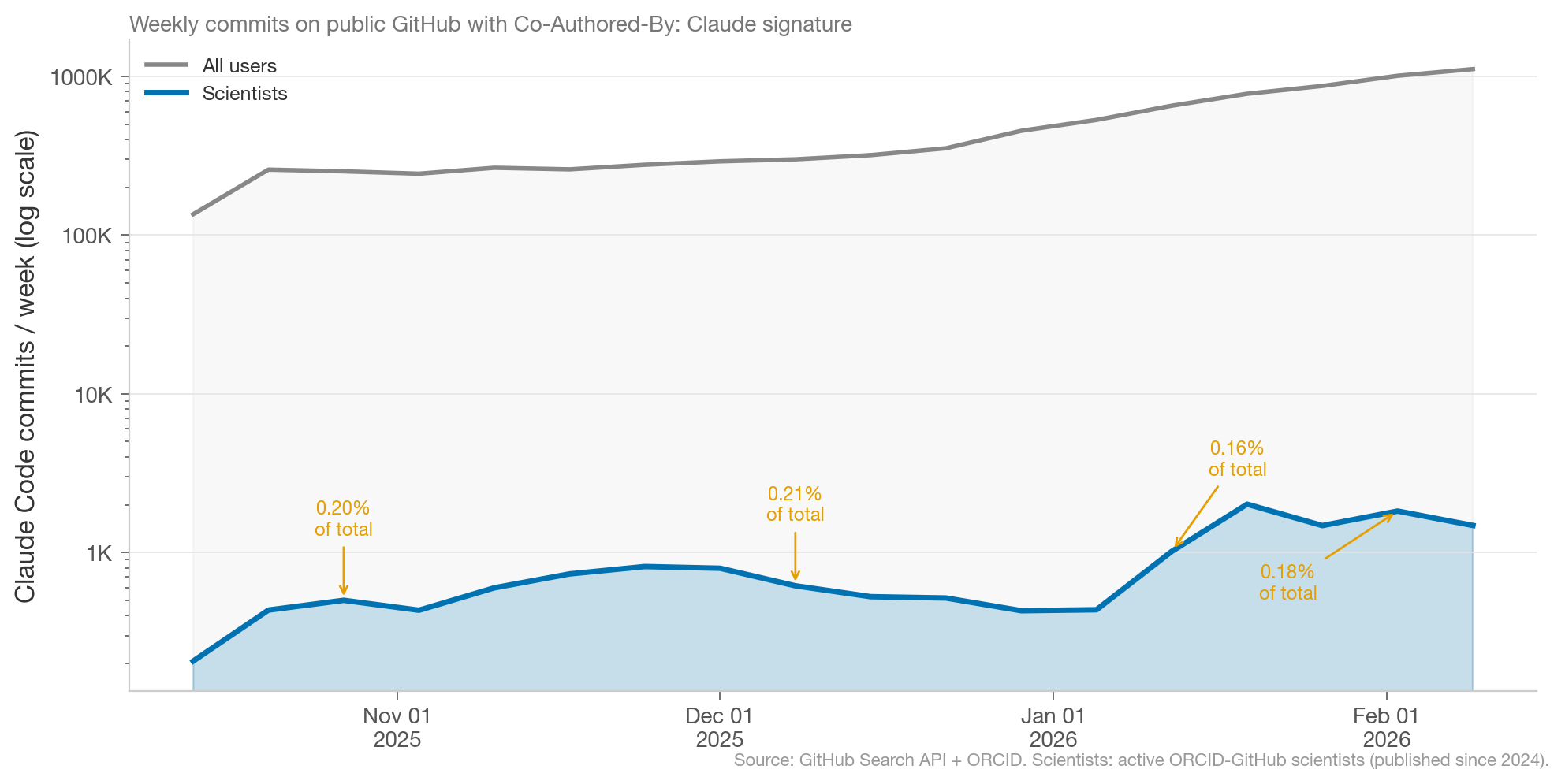
Scientists are responsible for a relatively stable proportion of total Claude Code commits, which suggests scientists are adopting Claude Code at roughly similar rates as other GitHub users.
What’s notable is the late January 2026 bump in scientist Claude Code commits. This suggests usage among scientists is still tied to academic cycles, but the late January bump is durable.
What Kinds of Scientists use Claude Code?
By Seniority
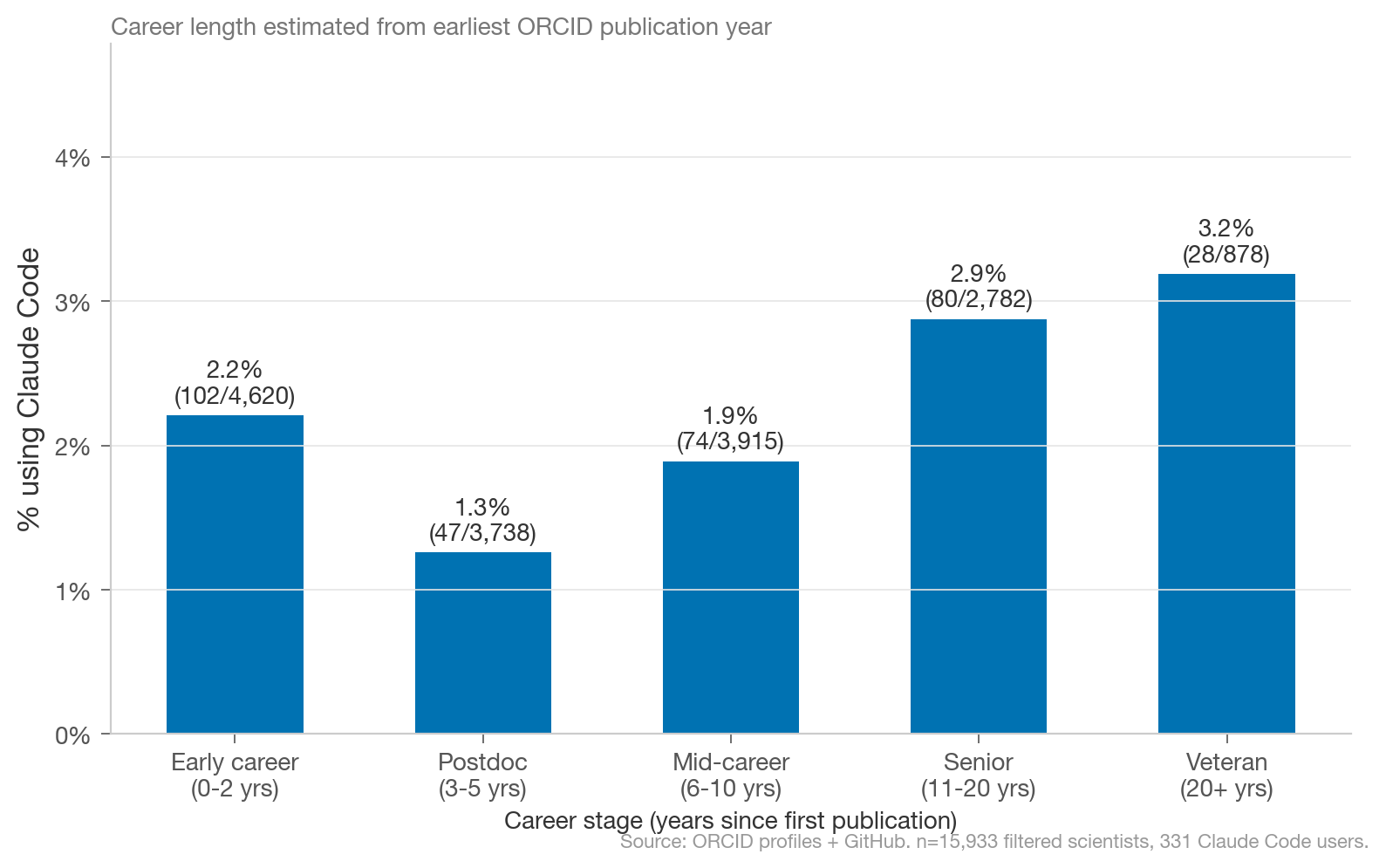
Somewhat surprisingly, across the 331 identified scientist Claude Code users within a population of 15,933 scientists, there is a U-shaped adoption curve by seniority. Scientists who first published papers 3-10 years ago are adopt at lower rates than early career or senior scientists.
This might make sense when you consider that risk aversion to new tools is highest during that career period. Early career scientists and post-tenure scientists have more freedom (and frankly, more time) to explore new tools.
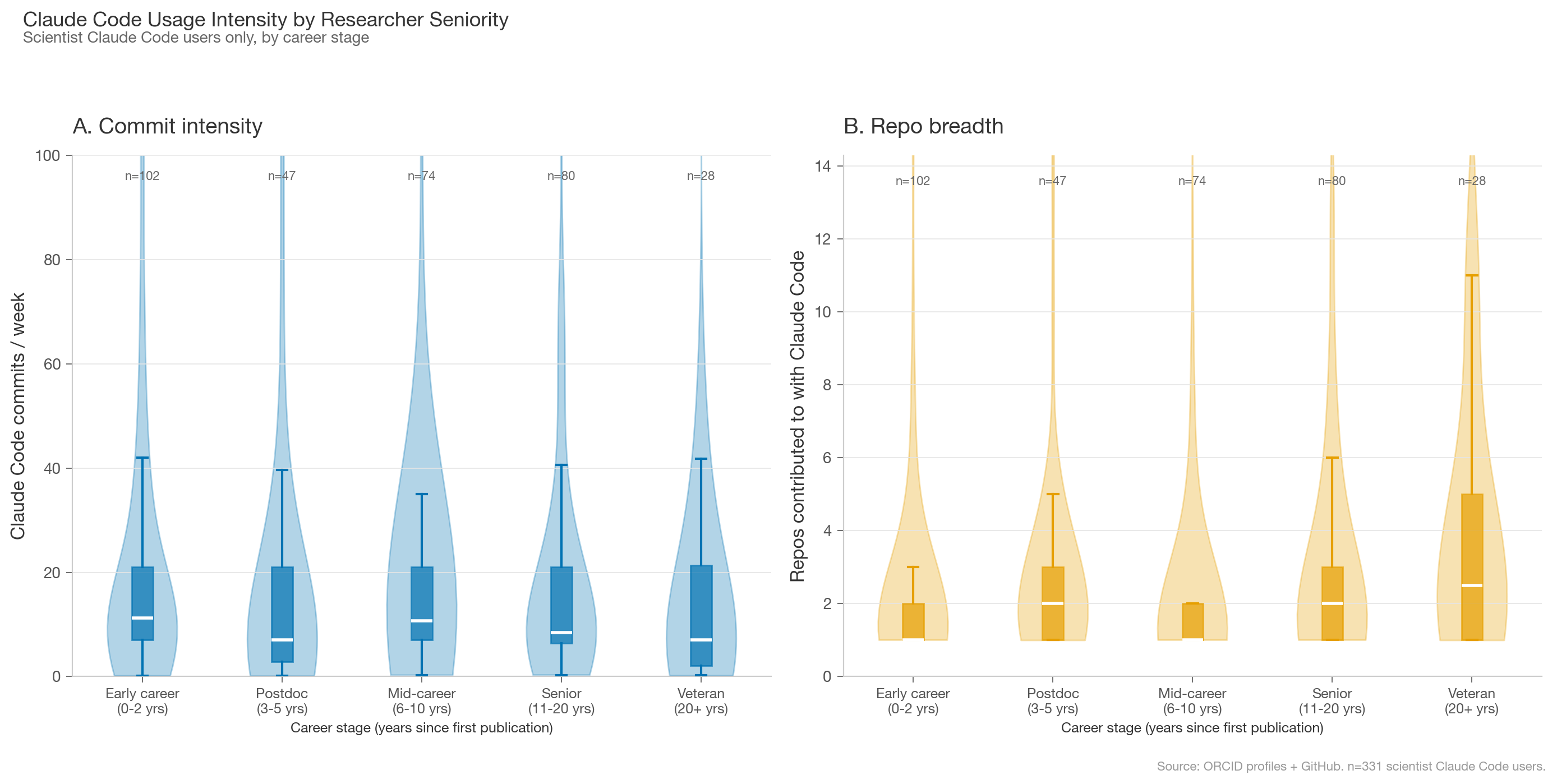
While Claude Code usage intensity is roughly the same across scientist seniority, veteran scientists are more likely to contribute across multiple repos. They were likely already involved in computational or open source work before Claude Code existed.
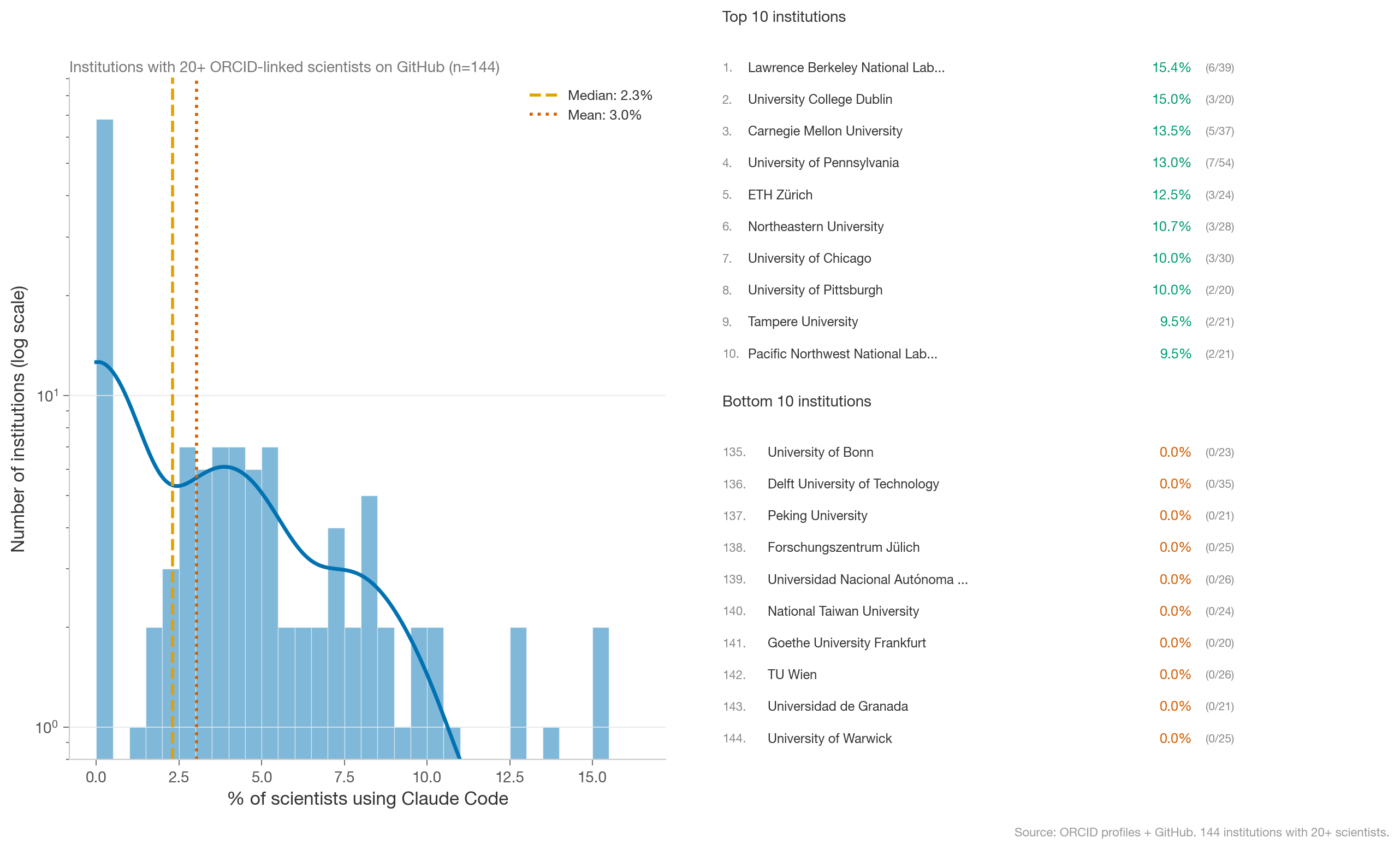
By Institutions
Because ORCID allows scientists to link to institutions, we can also identify institution-level adoption. After filtering for institutions with 20+ scientists linked on ORCID with Github, the vast majority of scientific institutions have zero public Claude Code users. Institutions with the highest adoption are U.S.-based Tier 1 universities.
(Note that scientists at those institutions may be using other coding models, or may be less likely to commit to public repos.)
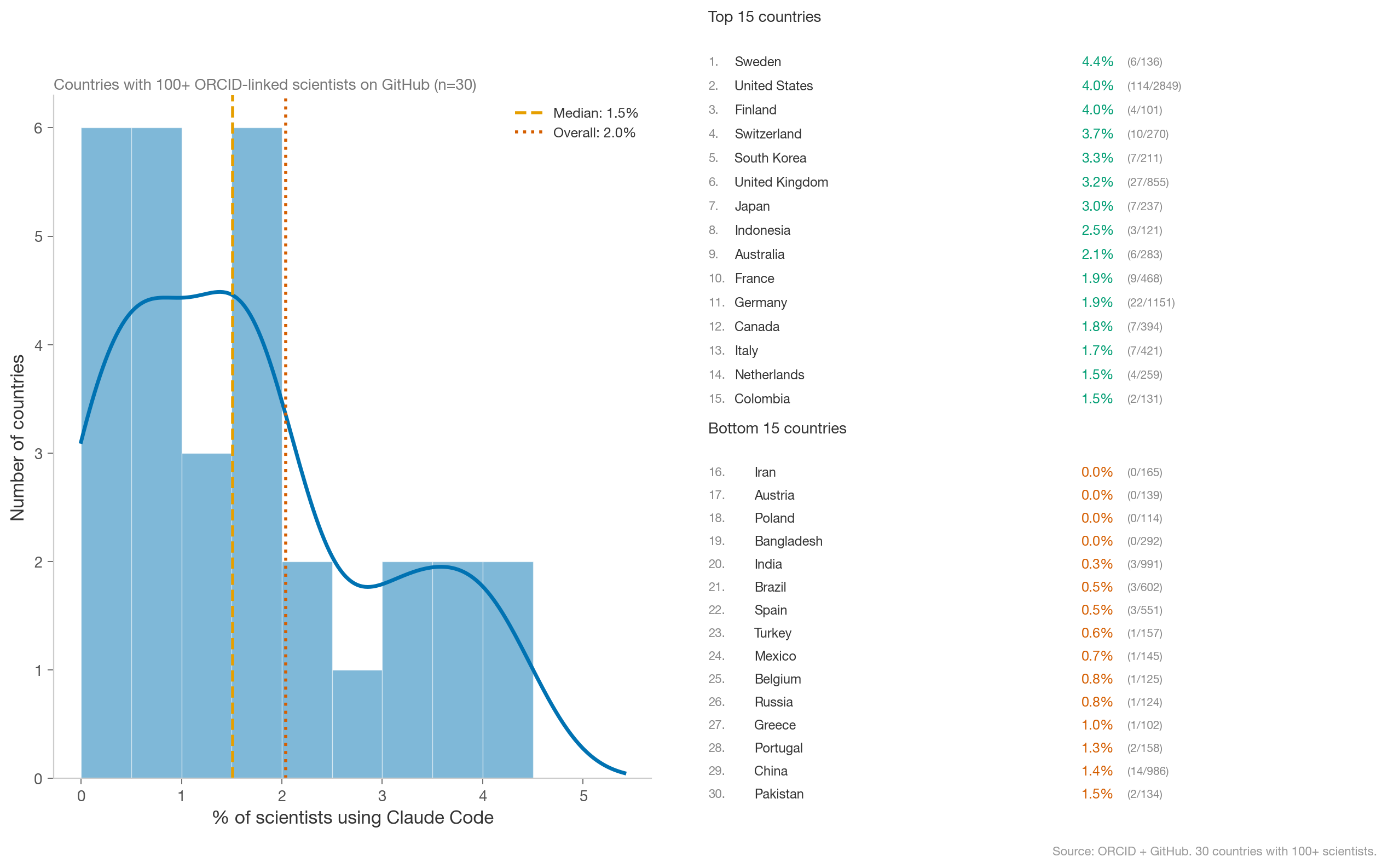
By Country
At the country level, scientists in the U.S., along with other western and east Asian countries (excluding China), are the highest adopters. More developing countries are some of the lowest.
A few caveats: the number of scientists using Claude Code varies by roughly 2 orders of magnitude between Sweden and the U.S., so these rankings should be treated as directional. ORCID adoption rates also vary by country, which confounds the comparison.
By Field
We identify field through mapping journals scientists publish in via Scopus journal topic mapping, with keyword-based fallback for preprint servers.
Economists and social scientists are the highest adopters. Mathematics and environmental science are the lowest. Adoption is fairly uniform across fields (1.4-3.4%), which I didn’t expect.
Field-level adoption is likely confounded by ORCID profile adoption within a given field. The low use of ORCID in computer science likely explains its surprisingly close-to-average adoption rate.
How do Scientists Use Claude Code?
Scientists who use Claude Code do so at roughly similar intensity as other public Claude Code GitHub users. They’re far more likely to use it for languages common in scientific computing: Python, R, and shell scripts. Scientist users are also more likely to work across multiple repos, which likely reflects that early adopter scientists were already active open source contributors.
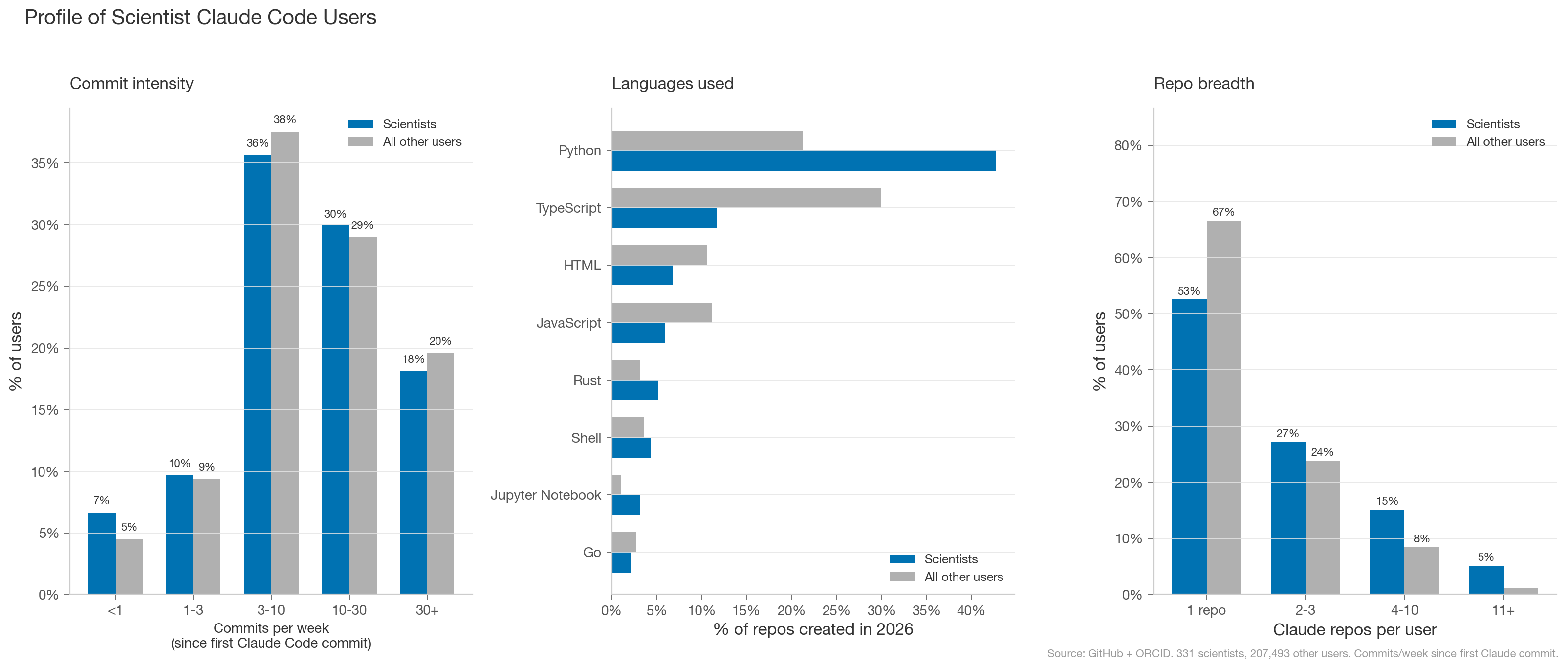
Examples of scientist Claude Code power users on github from this analysis include:
@williamjameshandley, Cambridge Royal Society University Research Fellow who uses bayesian machine learning for early universe cosmology
@cmungall, Lawrence Berkeley National Lab scientist and department head working on life sciences computational techniques
@cranmer, physics professor at UW Madison working at intersection of machine learning and particle physics
@edeno, computational research scientist in Dr. Loren Frank’s lab at UCSF focused on developing scalable, interpretable algorithms and tools to decode, categorize and visualize neural representations.
Only one repo has seen multiple claude code commits from multiple scientists in our admittedly limited datset: Disorder Mechanisms Knowledge Base (dismech) under the Monarch Initiative.
What comes next?
Accelerating the adoption of AI coding tools by scientists should be a national imperative and a key policy metric.
So, how do we drive adoption of AI coding tools among STEM graduate students?
One excellent approach is through hackathons, which create positive social spaces for graduate students to experiment and try something new. At Renaissance Philanthropy, we’ve supported an autonomous microscopy hackathon and I hope to support others that drive the adoption of coding tools for domain specific science workflows.6 Another perspective I’ve been exploring is viewing AI as a new science instrument, which lets us examine the history of science for how new instruments are adopted and successfully integrated into scientific workflows (or not).7
The science hackathons I’ve seen are mostly driven at a PI level or even by undergraduate clubs, rather than top-down. But enabling enterprise access is an important barrier, and one that (based on my conversations with university administrators) is still challenging for AI labs to crack. Google still has an edge here.8
While hackathons expand top of funnel initial engagement, there is also plenty of tool building left to do. From domain-specific plugins for specific workflows to designing new UIs for how to interact with scientific agents, accelerating adoption of AI coding agents increases the surface area for exploration and discovery. And the countries whose graduate students are first to internalize these tools into their daily research workflows will compound that advantage for years.
We are still so early. And there is still so much more to be done.
There are obviously many other important policy factors for how we fully realize the benefits of AI for Science but “every STEM graduate student using best AI coding tools” is an important step 0.
Motivated by the need for collective sensemaking around how AI is actually being used and diffused in the real-world economy, I started Diffuse AI with a few friends to collect contributing pieces on how AI is being used. First piece coming out later this month!
Removing this criterion crowds in many former graduate students who are now working in the private sector or on open source projects outside of academia, which are interesting, but muddy the analysis as they are no longer actively engaged in “science”.
Entirely made with Claude Code. Although I realize my github was not in my ORCID, so I am not represented in this dataset.
This analysis was drawn from Claude Code commit data on Github from Oct 15, 2025 to Feb 15, 2026. Scientists who started using Claude code after Feb 15, 2026 will not be captured in the dataset.
We’ll also have an upcoming Diffuse AI case study on how hackathons drive adoption of AI in scientific communities!
Mathematica and Matlab are other models of how companies drive adoption of specific software user tools.
Apparently even very simple enterprise features, like enabling per-seat token limits rather than an enterprise-wide uncapped $/M tokens plan, are not uniformly provided by AI labs.
Charles, excellent piece. Your framing of “AI as a scientific instrument” is interesting and it opens up new pathways to encourage adoption, like your experiments with hackathons.
I think another analogous way to think of it—for the purpose of identifying other techniques to encourage adoption—is as a new “approach” to implementing the scientific method. I found this analogy to be consistently true when working to influence more scientists, technologists, engineers, and program managers to leverage novel approaches, like prize competitions or advanced market commitments in their work. Those approaches can be very powerful to make progress on exploring hypotheses, solving problems, and engaging new and existing communities. Using AI forces you to also rethink how you identify hypotheses, pair possible problems and solutions, and work with agents and other knowledge domains to make progress on your problem. That requires not only using a new instrument, but also deep thinking about how you structure your work.
Creating environments for people to rethink their work—beyond the early adopters and innovators—is very hard. There is much to explore in this space.
Super interesting! Another possible reason for low adoption: they first tried claude code/LLMs for coding early on, back when they were not nearly as good.
I tried Claude Code when it first released in Feb 2025 and wasn't super impressed. I "re-discovered" it just a few weeks ago at TreeHacks , and was blown away by how good they were. Now that + Codex + claude cowork have become indispensable for me, in a matter of weeks.